

Hi everyone, this is Moah. I’m the tech lead on Stellaris and today I’m here to talk about the free 2.3 "Wolfe" update that will be arriving together with Ancient Relics, and what it brings to the table in terms of tech.
Stellaris is going 64 bits.
People have been clamoring for this for a while now, and various factors have led us to finally do this for this patch. I should temper your expectations though: while many have claimed that this would be a miracle cure for all their issues with Stellaris, the reality is somewhat more tame.
What does it mean?
The one solid benefit is that Stellaris is no longer limited to 4gb of memory, and won’t crash anymore in situations where it was reaching that limit. For people who play on huge galaxies, with many empires, many mods or well into 3000s, this will be a boon.
In terms of performance, though, it doesn’t change much. Without drowning you in technical details, let’s just say that some things go faster because you handle more data at once, some things go slower because you have more data to handle. In the end, our measurements have shown no perceptible difference.
Finally, the last effect of switching to 64 bits is that the game will no longer playable on 32 bits computers or OSes. We don’t think this will affect many people, but there you have it.
What about Performance?
I know that’s everyone’s favourite question, so let’s do our best to talk about it. First, let me dispel some notions floating around in various forums: Stellaris does use multithreading, and we’re always on the lookout for new things to thread. In fact between 2.2.0 and 2.2.7, a huge effort was made to thread jobs and pops, and it’s one of the main drivers of performance improvement between these version.
Pops and jobs are indeed what’s consuming most of our CPU time nowadays. We’ve improved on that by reducing the amount of jobs each pop evaluate. We’ve also found other areas where we were doing too much work, and cut on:
Modifiers
One thing that sets Stellaris apart from other PDS title is how much we use (or abuse) modifiers. Everything is a modifier. Modifiers are modified by other modifiers themselves modified by other modifiers, and sometimes by themselves. It’s quite hard to follow, and leads to every value being able to change at any time without your noticing.
“Why don’t you just compute jobs when a new one appears?” has often been asked around these parts. Well, a short answer to that is it’s really hard to know when a new job appears. You can get jobs from any modifier to: country, planet, pops. Each of these can get modifiers from ethics, traditions, perks, events, buildings, jobs, country, planets, pop, technology, etc.
Until now we were trying to calculate modifiers manually, forced to follow the chain in its entirety: when you recompute a country modifier, you then calculate their planets modifiers, and then each planet would recalculate their pops modifiers. Some of our freezes were just that tangled ball of yarn trying to sort itself out.
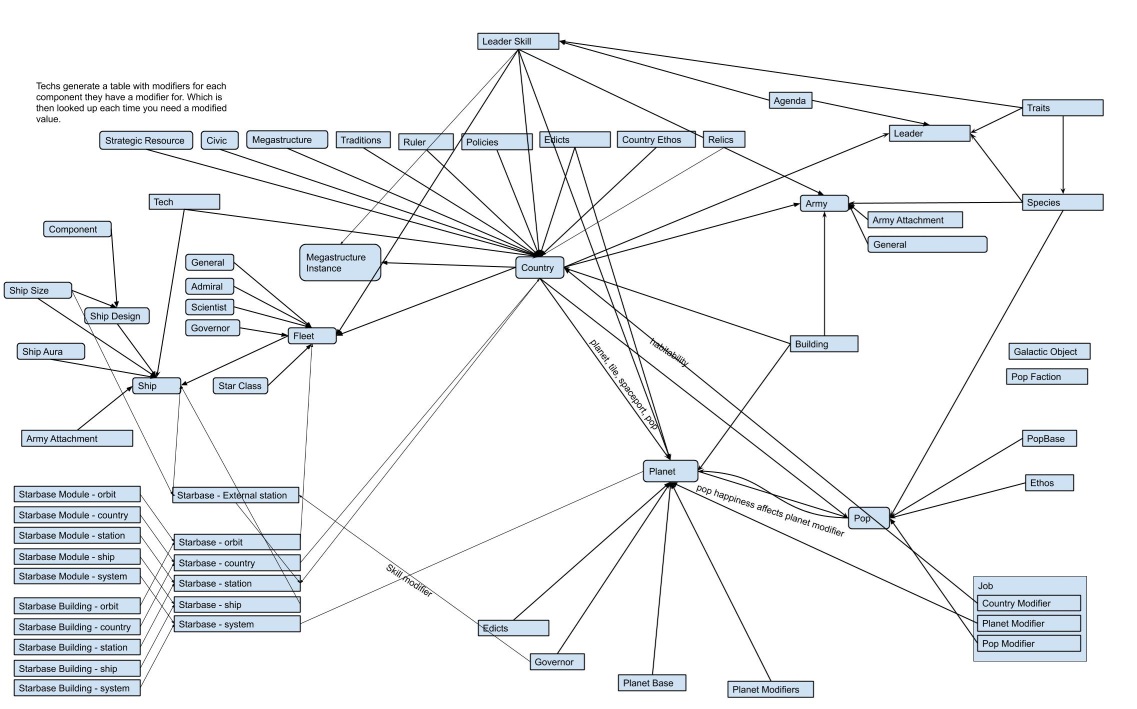
This is our modifier flow charts. It’s not quite up to date, but gives you an idea of the complexity of the system (Unpolished because it’s a dev tool, and not made for the article).
No More!
For 2.3 “Wolfe” we have switched to a system of modifier nodes, where each node register what node they follow, and is recalculated when used, following the chain itself. We have modifiers that are more up to date, and calculated only when needed. This also reduces the number of pointless recalculations.
This system has shown remarkable promise, and cut the number of “big freezes” happening around the game (notably after loading, for example). It has some issues, but as we continue working with it, it’ll get better and help both with performance and our programmers’ sanity.
So, what’s the verdict?
In our tests, 2.3 “Wolfe” is between 10% and 30% faster than 2.2.7 right now. Hopefully it’ll stay that way until release, but the nature of the beast is that some of these optimizations break things and fixing the issues negate them, so we can’t promise anything.
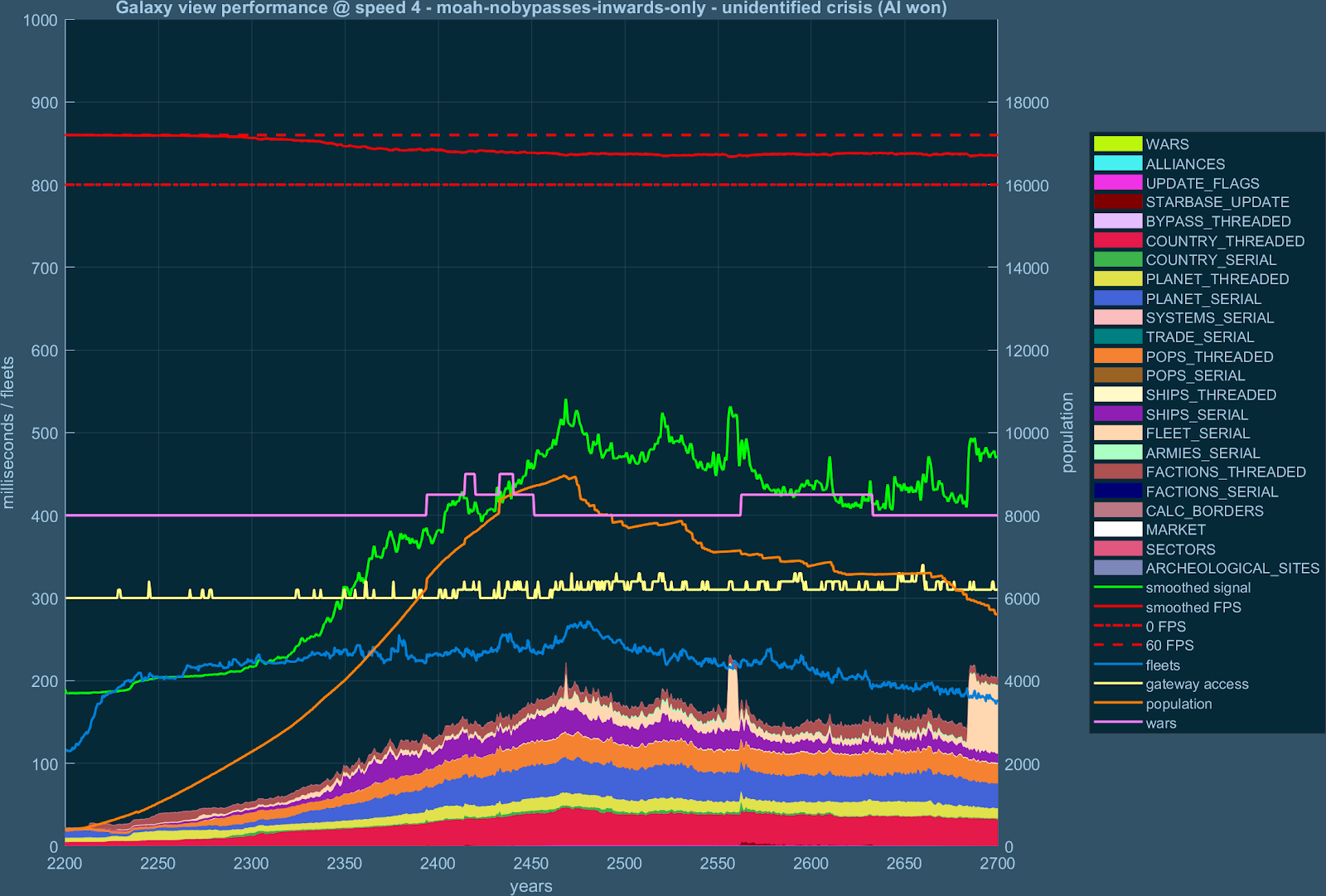
Measurements provided by @sabrenity , using detailed info from the beta build. It’s worth noting the “SHIPS_SERIAL” purple line has since been eliminated.
AI
Another forum favorite, we have done some improvements to the AI. First, with @Glavius ’s permission, we’ve used his job weights to improve general AI job distribution. We’ve also done the usual pass of polish and improvements, and of course taught the AI how to use all our new features.
What else is new?
We’re also getting a new crash reporter that will send your crash report as soon as they happen rather than next time you start the game. We’ve improved our non-steam network stack for connectivity issues, etc.
All right, enough of my yammering. This has turned into a GRRM length novel, and even though there are many more areas we could cover, we’ll just turn this for your perusal.
Stellaris is going 64 bits.
People have been clamoring for this for a while now, and various factors have led us to finally do this for this patch. I should temper your expectations though: while many have claimed that this would be a miracle cure for all their issues with Stellaris, the reality is somewhat more tame.
What does it mean?
The one solid benefit is that Stellaris is no longer limited to 4gb of memory, and won’t crash anymore in situations where it was reaching that limit. For people who play on huge galaxies, with many empires, many mods or well into 3000s, this will be a boon.
In terms of performance, though, it doesn’t change much. Without drowning you in technical details, let’s just say that some things go faster because you handle more data at once, some things go slower because you have more data to handle. In the end, our measurements have shown no perceptible difference.
Finally, the last effect of switching to 64 bits is that the game will no longer playable on 32 bits computers or OSes. We don’t think this will affect many people, but there you have it.
What about Performance?
I know that’s everyone’s favourite question, so let’s do our best to talk about it. First, let me dispel some notions floating around in various forums: Stellaris does use multithreading, and we’re always on the lookout for new things to thread. In fact between 2.2.0 and 2.2.7, a huge effort was made to thread jobs and pops, and it’s one of the main drivers of performance improvement between these version.
Pops and jobs are indeed what’s consuming most of our CPU time nowadays. We’ve improved on that by reducing the amount of jobs each pop evaluate. We’ve also found other areas where we were doing too much work, and cut on:
- Ships calculating their daily regeneration when they’re at full health
- Off-screen icons being updated
- Uninhabitable planets doing the same evaluations as populated planets
Modifiers
One thing that sets Stellaris apart from other PDS title is how much we use (or abuse) modifiers. Everything is a modifier. Modifiers are modified by other modifiers themselves modified by other modifiers, and sometimes by themselves. It’s quite hard to follow, and leads to every value being able to change at any time without your noticing.
“Why don’t you just compute jobs when a new one appears?” has often been asked around these parts. Well, a short answer to that is it’s really hard to know when a new job appears. You can get jobs from any modifier to: country, planet, pops. Each of these can get modifiers from ethics, traditions, perks, events, buildings, jobs, country, planets, pop, technology, etc.
Until now we were trying to calculate modifiers manually, forced to follow the chain in its entirety: when you recompute a country modifier, you then calculate their planets modifiers, and then each planet would recalculate their pops modifiers. Some of our freezes were just that tangled ball of yarn trying to sort itself out.
This is our modifier flow charts. It’s not quite up to date, but gives you an idea of the complexity of the system (Unpolished because it’s a dev tool, and not made for the article).
No More!
For 2.3 “Wolfe” we have switched to a system of modifier nodes, where each node register what node they follow, and is recalculated when used, following the chain itself. We have modifiers that are more up to date, and calculated only when needed. This also reduces the number of pointless recalculations.
This system has shown remarkable promise, and cut the number of “big freezes” happening around the game (notably after loading, for example). It has some issues, but as we continue working with it, it’ll get better and help both with performance and our programmers’ sanity.
So, what’s the verdict?
In our tests, 2.3 “Wolfe” is between 10% and 30% faster than 2.2.7 right now. Hopefully it’ll stay that way until release, but the nature of the beast is that some of these optimizations break things and fixing the issues negate them, so we can’t promise anything.
Measurements provided by @sabrenity , using detailed info from the beta build. It’s worth noting the “SHIPS_SERIAL” purple line has since been eliminated.
AI
Another forum favorite, we have done some improvements to the AI. First, with @Glavius ’s permission, we’ve used his job weights to improve general AI job distribution. We’ve also done the usual pass of polish and improvements, and of course taught the AI how to use all our new features.
What else is new?
We’re also getting a new crash reporter that will send your crash report as soon as they happen rather than next time you start the game. We’ve improved our non-steam network stack for connectivity issues, etc.
All right, enough of my yammering. This has turned into a GRRM length novel, and even though there are many more areas we could cover, we’ll just turn this for your perusal.
") finnaly performance. only department where stellaris was lacking is now good. Never disapointed in stellaris.
finnaly performance. only department where stellaris was lacking is now good. Never disapointed in stellaris.